
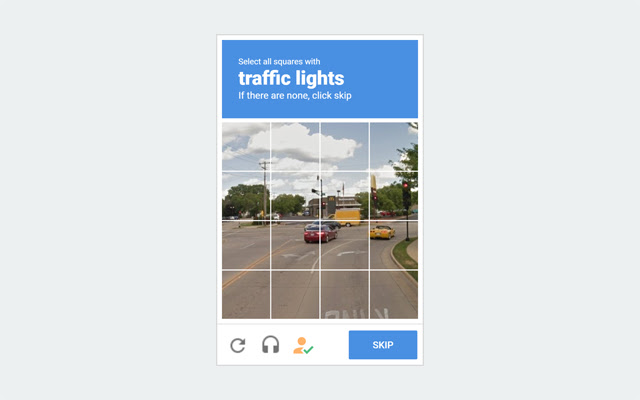
CAPTCHA son las siglas de Completely Automated Public Turing test to tell Computers and Humans Apart (prueba de Turing completamente automática y pública para diferenciar ordenadores de humanos). Son pruebas desafío-respuesta controladas por máquinas (no es necesario ningún tipo de mantenimiento ni de intervención humana para su realización, y es implementado en un ordenador) que son utilizadas para determinar cuándo el usuario es un humano o un programa automático (bot). Es similar a una test de Turing pero con la diferencia de que en los test de Turing el juez es un humano. Por ello, a los captchas a veces se les llama test de Turing inverso o prueba de Turing inversa; esta denominación es un tanto ambigua, ya que eventualmente puede significar que los participantes o usuarios tratan de convencer a alguien (humano o autómata) de que ellos no son humanos.
Lo ideal es que el algoritmo utilizado sea público. De esta forma la ruptura de un captcha pasa a ser un problema de inteligencia artificial y no la ruptura de un algoritmo secreto.
En Internet se ofrecen varios servicios de forma gratuita con la esperanza de que los ingresos publicitarios o la venta de los datos de los usuario generen ganancias. La suposición clave detrás de los modelos de negocio empleados por estos sitios es que los ojos humanos están viendo esos anuncios. Sin embargo estos servicios los pueden usar programas automáticos para obtener dinero. Por ejemplo, las cuentas de correo electrónico basadas en la web se pueden usar para enviar correo no deseado o se pueden usar servicios de redes sociales o servicios que permiten publicar contenidos para servidores de comando y control para una botnet. Los CAPTCHA se desarrollaron como un medio para limitar la capacidad de los atacantes de escalar sus actividades utilizando medios automáticos.
El término se empezó a utilizar en el año 2000 por el guatemalteco Luis von Ahn, así como por Manuel Blum y Nicholas J. Hopper de la Universidad Carnegie Mellon, junto a John Langford de IBM.
Inicialmente los captcha consistían en que el usuario introducía correctamente un conjunto de caracteres que se muestran en una imagen distorsionada que aparece en pantalla. Se supone que una máquina no es capaz de comprender e introducir la secuencia de forma correcta, por lo que solamente el humano podría hacerlo.
Poco a poco, los programa han ido aprendiendo a resolver este tipo de problemas. Esto ha obligado al CAPTCHA a evolucionar dando lugar a distintos tipos de CAPTCHAs.
Los captchas son utilizados para intentar evitar que programas automatizados, puedan utilizar ciertos servicios. Por ejemplo, para que no puedan participar en encuestas o foros de discusión, registrarse para usar cuentas de correo electrónico o enviar correo basura (para enviar un correo se obliga al usuario a pasar el test).
El uso de mano de obra humana para resolver CAPTCHA efectivamente esquiva su punto de diseño. Además, la combinación de acceso a Internet barato y la naturaleza de los productos básicos de los CAPTCHA de hoy en día ha globalizado el mercado de solución; de hecho, el costo mayorista ha disminuido rápidamente a medida que los proveedores han reclutado trabajadores de los mercados laborales de menor costo. Hoy en día, hay muchos proveedores de servicios que pueden resolver grandes cantidades de CAPTCHA a través de servicios a pedido con precios tan bajos como 1 dólar por mil.
Aunque los CAPTCHA han sido originalmente diseñados para impedir que el software OCR reconozca los caracteres de las imágenes generadas, existen proyectos de investigación que han probado que es posible saltarse muchos CAPTCHA con programas que han sido específicamente diseñados para un tipo determinado de CAPTCHA. Para CAPTCHA con letras distorsionadas, la aproximación típica es seguir los siguientes pasos:
- Eliminación del ruido de fondo, por ejemplo con filtros de color y detecciones de líneas finas.
- Segmentación, por ejemplo partiendo la imagen en segmentos que contienen una sola letra.
- Identificar la letra de cada segmento, y así utilizar la información extraída de la imagen.
El paso 1 es típicamente muy fácil de automatizar. En 2005, se mostró que un algoritmo de una red neuronal tiene un menor margen de error que los humanos resolviendo el paso 3. La única parte donde los humanos superan a las máquinas es en el paso 2. Si el ruido de fondo consiste en formas similares a letras y las letras están unidas a este ruido, la segmentación se hace casi imposible con el software actual. Por lo tanto, un CAPTCHA efectivo debería enfocarse en el paso 2, la segmentación.














Leave a Reply